BAIR이 가장 주목하는 AI app 트렌드: Compound AI Systems는 뭘까?
Mar 10, 2024
투자자들 사이 AI 생태계에 대해 가장 치명적인 오해는 LLM과 AI 어플리케이션을 동일 시 취급하는 것이라고 생각합니다.
저희가 자주 사용하는 ChatGPT, Perplexity 등 AI 어플리케이션은 모두 Compound AI System입니다.
예를 들어, Perplexity 내에선 인터넷 브라우징, source tagging, 파일 업로드 등 다양한 기능이 구현됩니다. Perplexity는 Claude-3, GPT-4, Mistral 등 모델을 사용하여 답변을 생성하지만 엄연히 “next word predictor”인 LLM과는 다르죠. LLM은 Perplexity, ChatGPT 등 어플리케이션을 구동하는 하나의 component일 뿐 입니다.
한 때는 GPT Wrapper이라고 사람들이 비아냥하기도 했었죠. 지금은 지난 10년+ 간 가장 강력했던 모노폴리인 Google Search 매출을 위협하는 아이템으로 성장했습니다.
AI 어플리케이션은 하나의 Foundation Model, 즉 모놀리스(monolith) 구조가 아니라 다양한 기능과 function으로 연결된 매우 복잡한 아키텍처로 구성되어 있습니다. 많은 개발자들이 LLM을 활용하여 어플리케이션을 만들면서 monolithic 구조 뿐만 아니라 여러 구성 요소가 포함된 복합 시스템을 활용하는 경우가 점점 많아지고 있습니다.
사용해보신 분들은 아시겠지만 Perplexity의 장점은 다른 툴(ChatGPT) 대비 매우 빠르고, 출처를 나타낸다는 것입니다. 이 것은 Perplexity가 LLM 외에도 다양한 기능들을 덧붙여 성능을 최적화한 것이고 이 Compound AI System의 아키텍처와 각 컴포넌트의 IP는 Perplexity의 주요 경쟁력입니다.
Berkeley AI 리서치 랩(BAIR)에선 Compound AI 시스템이 2024년 가장 중요한 트렌드라고 주장합니다. 금번 블로그 포스트는 해당 블로그 내용을 분석해보겠습니다.
Compound AI System은 무엇인가?
저자들은 Compound AI 시스템을 아래와 같이 정의하고 있습니다.
We define a Compound AI System as a system that tackles AI tasks using multiple interacting components, including multiple calls to models, retrievers, or external tools.
반면에 AI 모델 (또는 단순 GPT-4 API 콜로 구동되는 어플)은 단순히 “statistical model” (e.g. 다음 토큰을 예측하는 것)일 뿐입니다.
개발자들은 왜 굳이 Compound AI 시스템을 사용할까?
개발자들은 AI 모델 한 번 콜 하는 것이 관리하거나 구축하는데 훨씬 편할텐데 왜 굳이 Compound AI 시스템을 만들까요?
1) 특정 Task에선 모델을 scaling하는 것보다 시스템 디자인 적으로 문제를 푸는 것이 효율적이다.
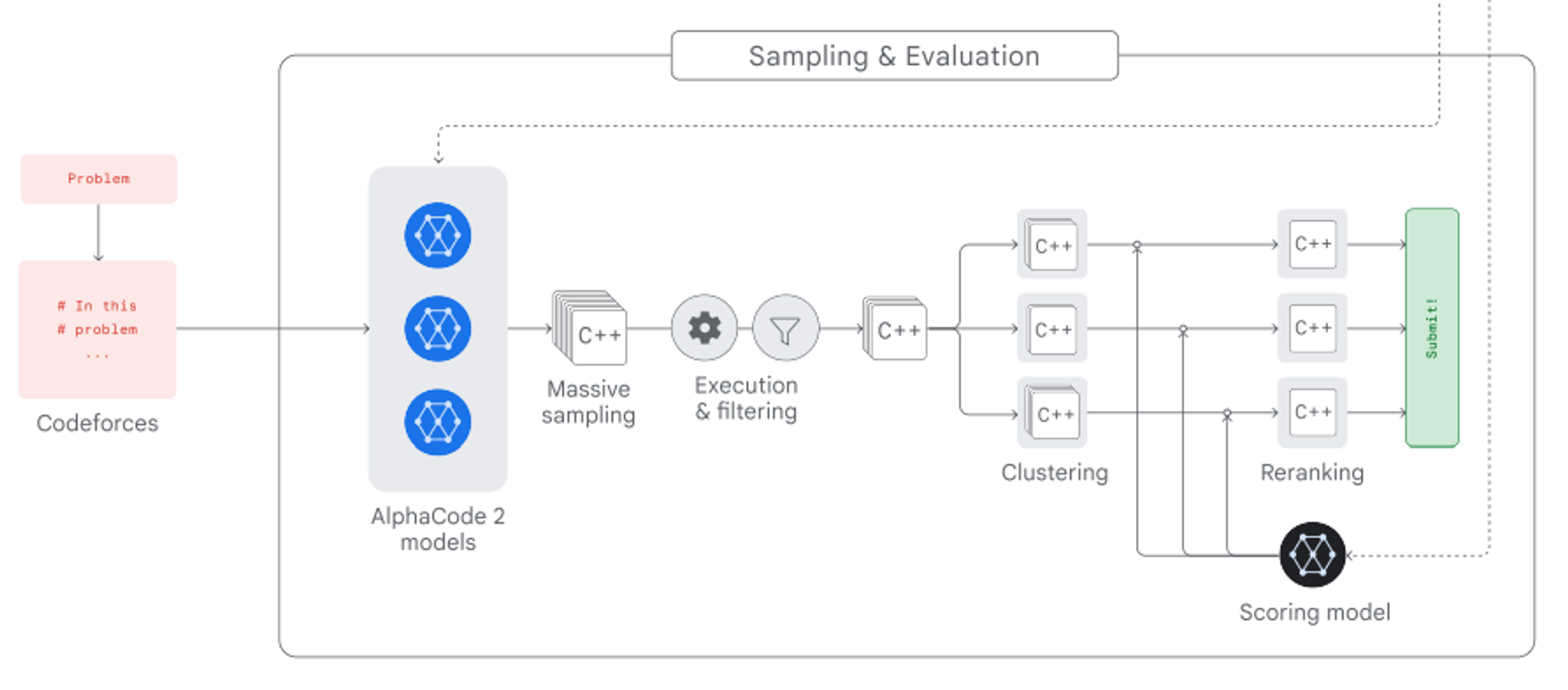
- 예를 들어, 특정 LLM이 코딩 문제 점수에서 30점을 받습니다. LLM의 training budget을 3배 늘려서 5점을 개선하는 것보다 시스템 디자인(LLM에게 샘플을 여러 개 뽑아 Ranking 한 후 답변 출력 등) 방법이 효율적인 방법으로 점수를 80점까지 개선했다는 결과도 있습니다 (e.g. AlphaCode).
2) 시스템은 “dynamic” 해야 한다.
- AI 모델들은 “static” 데이터셋으로 학습되기 때문에 knowledge cut-off 등 문제가 발생하며 이를 보완하기 위해 RAG, 인터넷 브라우징 등을 사용
- 다양한 정보 권한이 있는 사람들이 같은 어플리케이션을 사용할 것이기 때문에 “access control” 등 기능도 중요 (e.g. answer a user’s question based only on files the user has access to)
3) AI Safety를 실현시키기 위해선 Compound 시스템이 필수.
- LLM은 “black box”입니다. 학습으로 어느 정도 컨트롤은 할 수 있겠으나 특정 하지 말아야 할 행동을 100% 막을 순 없습니다. 모델 아키텍처 내에 인풋/아웃풋을 관제하는 가드레일 기능이 LLM과 별도로 AI 어플리케이션 아키텍처 내 존재해야 합니다.
4) 각 개발자마다 목표가 다르다.
- 각 AI 모델은 어느 정도 고정된 퀄리티와 비용이 예상됩니다. 다만, 어플리케이션 개발자마다 니즈가 다릅니다.
- 법률 AI 챗봇의 경우, 사용자는 비용은 상관 없으니 매우 정확한 답변이 필요할 수도 있습니다. 정확성이 보장되고 액션까지 취해준다면 실제 변호사 비용의 50% 수준까진 소비자는 충분히 지불할 용의가 있겠죠.
- 예를 들어, 정확도를 보장하기 위해 5개의 LLM을 각각 50x+ API 콜을 하며 RAG까지 사용하여 Fact-checking을 하는 등 개발자는 속도와 비용은 포기하고 정확도를 최적화하기 위해 해당 로드맵을 선택할 수 있습니다.
- AI 어플리케이션이 monolith 구조라면 이런 유동적인 튜닝이 불가능합니다.
Compound AI System 예시
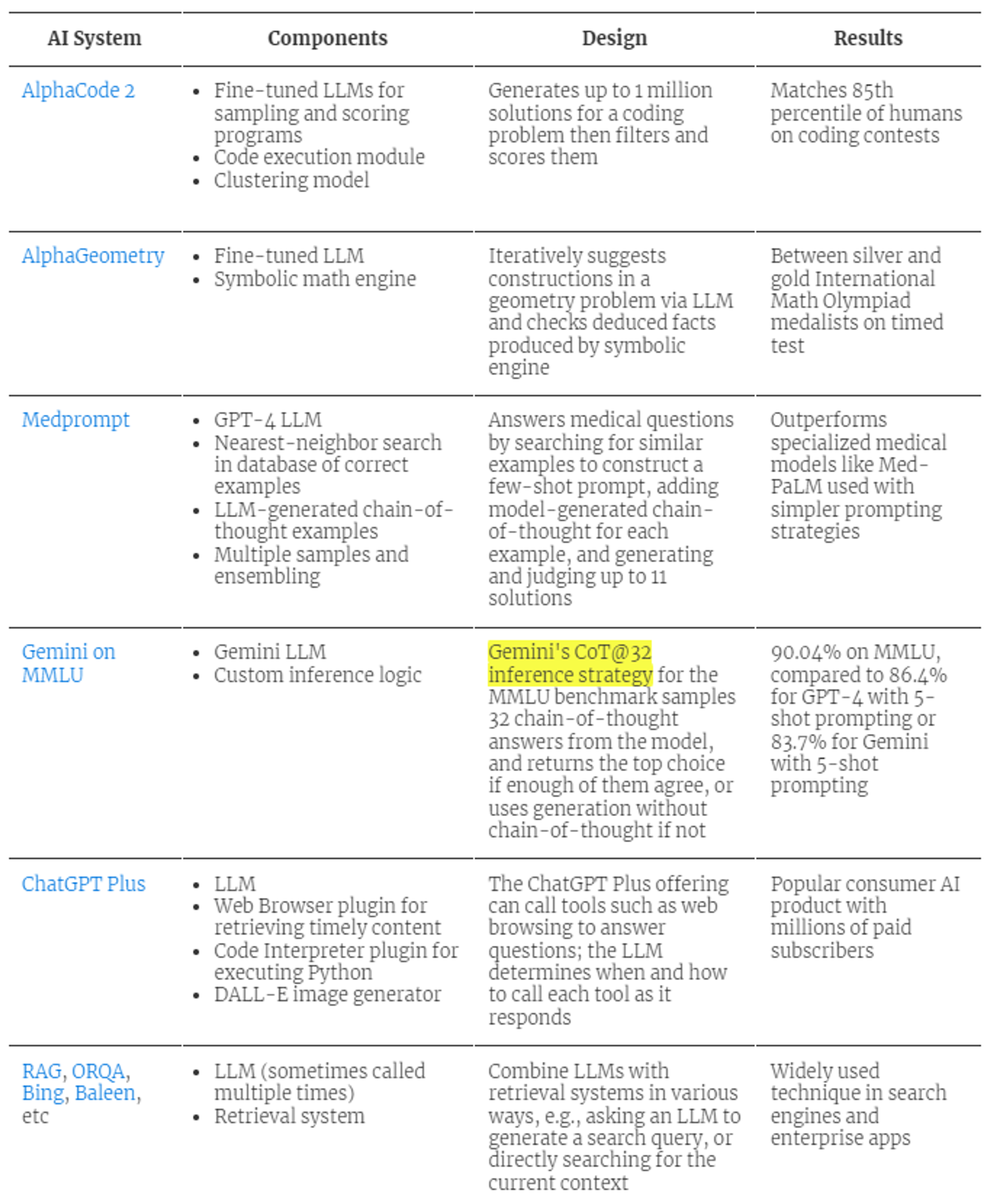
Compound AI 시스템 예시론 AlphaCode, Perplexity, ChatGPT Plus 등이 있습니다. 한번의 API 콜로 끝나는 것이 아니라 각 어플마다 달성하고자 하는 목적에 따라 최적화된 시스템 디자인을 활용합니다.
Databricks에 의하면 LLM 어플리케이션 중 60%는 RAG를 사용하며 30%는 multi-step chain을 활용한다고 합니다. 연구원들 또한 한 번의 LLM 콜보다 복잡한 시스템 디자인으로 결과를 개선하고 있습니다.
- AlphaCode 2는 코딩 문제를 받으면 100만개의 솔루션을 찍어내고 scoring과 reranking 과정을 거쳐 더 정확한 아웃풋을 출력합니다.
- Microsoft는 chaining 전략으로 의료 검사에서 GPT-4 정확도를 9% 초과하는 결과를 공개한 바 있습니다.
- Google Gemini는 런칭 당시 Cot-32 인퍼런스 전략을 사용하면서 GPT-4 대비 우수한 MMLU 벤치마크 성적을 강조하기도 했습니다.
- 다만, Cot-32는 모델을 32번 콜하는 반면, GPT-4의 MMLU 스코어는 1번의 API콜이어서 apples-to-apples 비교가 아니라는 비판이 많았습니다.
Compound AI 시스템이 매우 exciting 한 이유는 단순 scaling(대기업 영역)만으로 아웃풋을 개선해 나갈 수 있는 것이 아니라 system design으로도 선도적인 AI 퀄리티를 얻을 수 있다는 점입니다.
주요 Challenges
1) 디자인
- 아키텍처를 어떤 방식으로 설계 해야 할지 막막합니다. 예를 들어, RAG 문서 전처리 단계에서만 개발자가 결정해야 할 옵션들의 경우의 수를 합쳐보면 총 3,600만 조합이 나옵니다. 개발자들은 자신의 서비스를 최적화하기 위해 이 무한한 공간을 탐색해야 합니다.

Langchain KR 밋업 “RAG 우리가 절대 쉽게 결과물을 얻을 수 없는 이유” - 이경록 (teddylee777@gmail.com)
- 또한, 개발자들은 제한된 리소스 (비용, 시간 등)을 어떻게 할애할지 디자인에 녹여내야 합니다. 예를 들어, 100ms 내 아웃풋을 제공해야 한다면 20ms를 RAG에 사용하고, 80ms를 LLM에 사용해야 할까요? 아님, 그 반대?
2) Optimization
- AI 모델 하나보다 복잡한 AI 어플리케이션을 optimize하는 것이 더 어렵습니다. AI 어플리케이션을 optimize하기 위해선 대부분의 경우, 모든 컴포넌트를 co-optimize해야 하는 작업이 있습니다. 단순히 Plug & Play가 가능한 영역이 아닙니다.
- 이 영역은 진행되고 있는 연구분야(예. DSPy)이며 지금으로썬 고통스럽고 반복적인 iteration/testing/evaluation을 거쳐야 할 것으로 보입니다.
3) Operation (Monitoring, DataOps, Security)
- Compound AI 시스템의 경우, MLOps가 매우 복잡해집니다.
- 예를 들어, 단순 한 번의 API 콜로 답변을 받는 것이 아니라 multi-step (reflection, external API 콜, multiple 콜, 에이전트 등)을 활용해서 답변을 받는 구조라면 어떤 방식으로 error를 트래킹하고 디버깅할 수 있을까요? (Evaluation 블로그 포스트)
Compound AI System의 파생 트렌드
- Abstraction Frameworks: 복잡한 AI 어플리케이션 구조를 직접 코딩을 하지 않을 수 있도록 abstraction framework을 제공해주는 LangChain, LlamaIndex, Microsoft의 Semantic Kernel가 큰 인기를 끌고 있습니다.
- AI Gateway / Routers: 사용자의 질문에 따라 적절한 LLM을 “routing”해주는 서비스(e.g. Martian, Databricks AI Gateway 등)도 인기입니다. 예를 들어, FrugalGPT의 경우, 개발자의 budget 내에서 최고의 답변 퀄리티를 제공할 수 있는 LLM으로 routing합니다. 이로 인해 답변 퀄리티를 4% 개선해주거나, 동일한 퀄리티에 비용을 90% 절감해줍니다.
- Evaluation: Compound AI 시스템의 경우, 어플리케이션 내 구동 시 각 Step과 아웃풋 마다 모니터링과 디버깅 기능이 매우 중요합니다 (e.g. Langsmith, Coxwave 등). Tech stack이 더욱 복잡해지면서 evaluation에 대한 니즈가 더욱 중요해지고 있습니다.
Is compound systems here to stay? (self-driving car analogy)
- 전 Google Brain의 Research Scientist이자 현재 Samaya AI 대표인 Maithra Raghu는 AI 앱을 자율주행 차와 비교(블로그)합니다.
We can walk through a concrete example by considering current AI systems for self-driving cars. These systems have multiple AI components, from a planning component, to detection components and components for data labeling and generation.
- 자율주행 차량도 하나의 모델로 모든 것을 구현하는 것이 아니라 각 버티컬 기능 별 특화된 Neural Network들이 조화롭게 협업하여 “자율주행” Function (specialized AI system)을 구현합니다.
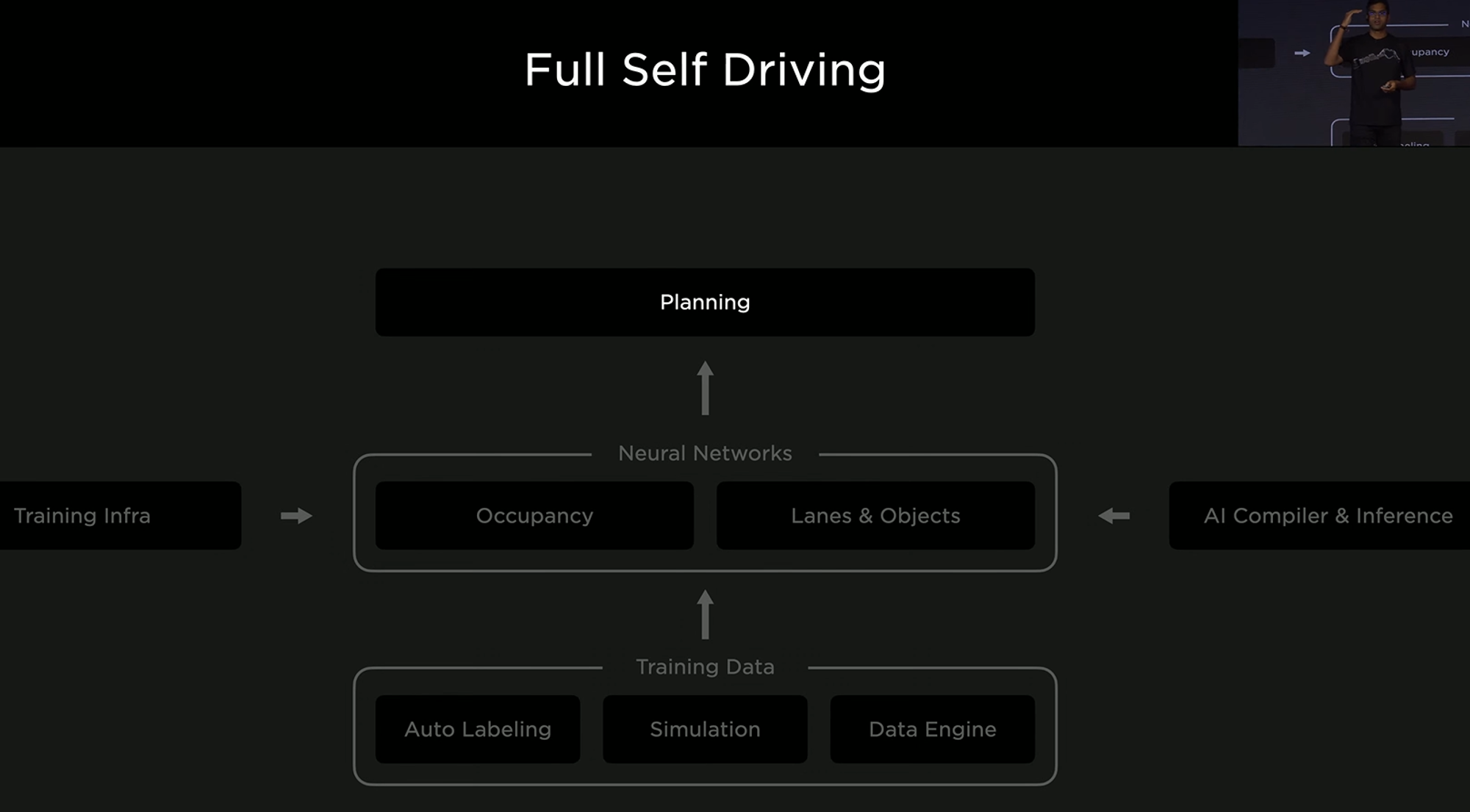
2022년 Tesla AI Day; 2021년에만 Tesla는 75,000 neural network 모델을 학습시키고 281개를 ship함.
- 기존 FSD 위에 General AI 모델이 이 워크플로우를 대체할 수 있을까요? Maithra는 재밌는 thought experiment를 제시합니다:
Imagine GPT-(4+n) is released, with remarkably useful capabilities, including for self-driving.We can’t instantly replace the entire existing system.So we identify the most useful capabilities of GPT-(4+n) and look at adding those in as another component, perhaps via an API call.This new system is then tested out, and inevitably, gaps in quality are identified.There is a push to address these gaps, and as they arise from a specific workflow (self-driving), workflow specific solutions are developed.The end result could have the API call completely replaced with a new, specialized AI component, or augmented with other specialized components.
- 만약에 자율주행 기능이 탑재된 GPT-N 모델이 나온다면 기존 시스템을 다 갈아엎지는 못할 것이고 부분적으로 테스팅 해나갈 것으로 봅니다. 예를 들어, Data Labeling 내 기능 중 하나를 general 모델로 갈아 끼웁니다.
- 하지만, Tesla의 차종, 수집 데이터 등에 최적화 되어 있지 않은 general 모델을 사용하다 보니 sub-par 퍼포먼스를 보입니다.
- Tesla는 이 performance gap을 없애기 위해 자신 use case에 맞는 specialized AI component로 general purpose AI를 대체합니다.
While this thought experiment might not be fully accurate, it illustrates how we may start with a general AI model, but then specialize it substantially to improve quality.In summary, (1) quality matters for high value workflows, and (2) specialization helps with quality.
Conclusion
LLM은 대체로 평준화 될 것으로 믿고 있습니다.
그렇기 때문에 AI 어플리케이션의 프로덕트 퀄리티는 LLM과 별개로 어떤 방식으로 compound AI system을 구축해서 target metric (스피드, 아웃풋 정확도 등)을 최적화하냐 게임으로 보여집니다.
그렇다면 AI 어플리케이션 회사를 검토할 때, “GPT-4보다 나은 점이 뭐죠?” 보다 더 좋은 guiding question은 아래와 같을 것 같습니다:
- 저희가 타겟하고 있는 워크플로우엔 왜 “specialized AI system”이 필요한가요?
- 이 워크플로우 내 잠재 고객이 필요로 하는 target metric은 무엇인가요? 그 target metric에 도달하는데 풀어야 할 bottleneck은 무엇인가요? (예. search, indexing, RAG pipeline, chaining 등)
- 저희는 어떤 AI 시스템 디자인으로 이 문제를 풀고자 할 것이며, 빠르게 실험하고 iterate할 수 있도록 dev cycle 내에서 어떤 정량적인 방법으로 evaluation을 가져가고 있나요?
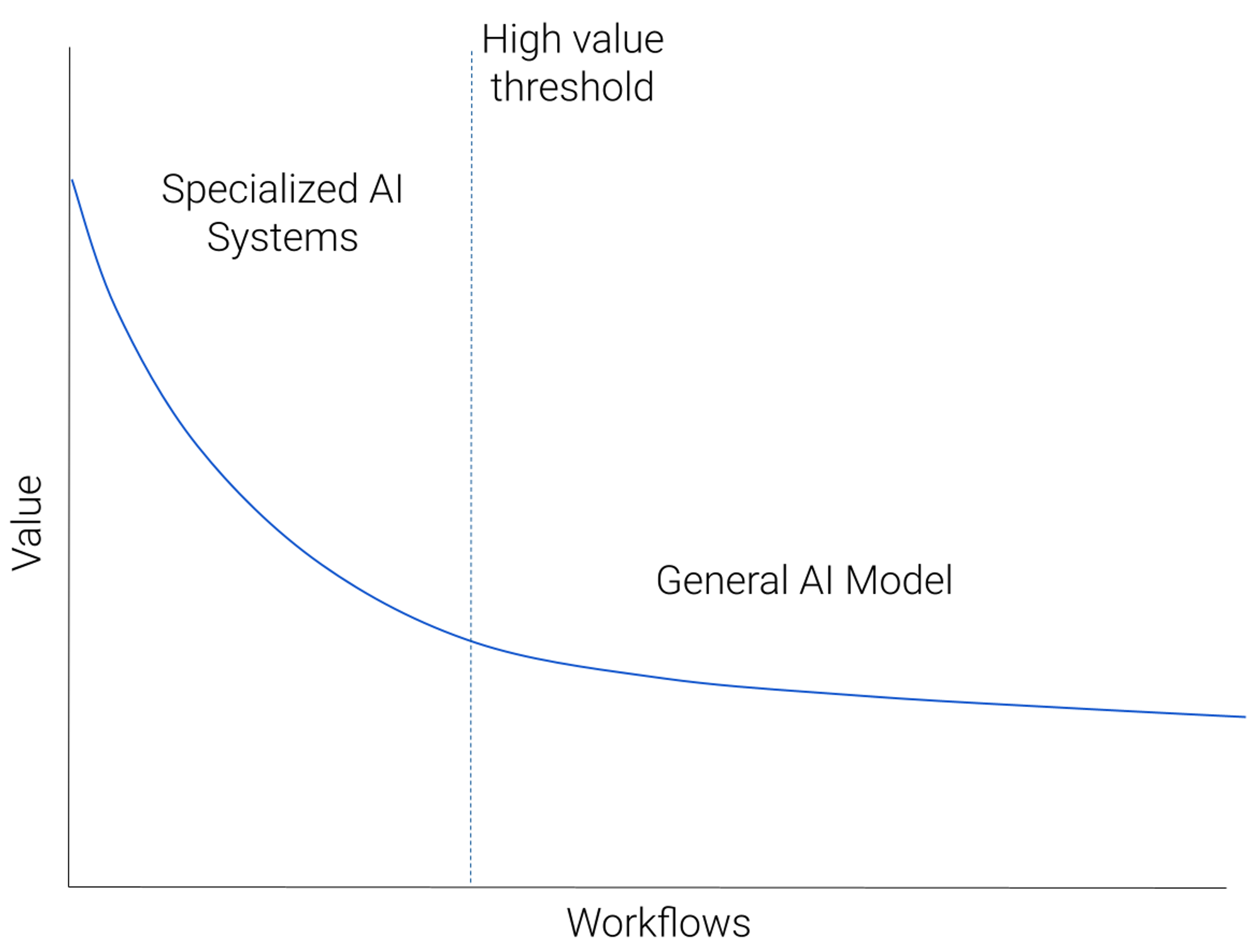
Imagine we took all workflows amenable to AI-based solutions, and plotted them in decreasing order of “value”. Value could be revenue potential, or simply utility to users. There would be a small number of very high value workflows — a large market or a large number of users with a clearly defined painpoint addressable by AI. This would descend to a long, heavy tail of diverse, but lower value workflows, representing the many custom predictive tasks that AI could help with.
Share article
Subscribe Newsletter
Stay connected for the latest news and insights.Get the latest news to stay informed.